
본 게시글은 [10분 테코톡] ✌️ 영이의 Replication을 들으며 작성한 글입니다.
Replication이란?
한 서버에서 다른 서버로 데이터를 동기화하는 것을 말한다.

- 원본 데이터를 가진 소스 서버
- 복제된 데이터를 가지는 레플리카 서버
Relication 서버를 구축하는 목적
- 스케일 아웃
갑자기 늘어나는 트래픽을 대응하는 데 유연한 구조이다.
- 데이터 백업
레플리카를 안하더라도 백업은 필요하다. 백업 과정은 실제 실행 중인 쿼리들에 영향을 줄 수 있으므로, 레플리카 서버에서 데이터 백업을 실행하여 소스 서버에서 백업 시 발생하는 문제들을 해결한다.
- 데이터 분석
분석용 쿼리는 대량의 데이터를 조회하고 쿼리 자체가 무거운 경우가 많다. 이를 소스 서버에서 진행할 경우 실제 서비스에 문제가 될 수 있다. 따라서 레플리카 서버에서 분석용 쿼리만 전용으로 수행하는 것이 좋다.
- 데이터의 지리적 분산
특정 지역에서만 제공하는 서비스는 많이 없다. 대부분 전세계적으로 서비스를 제공한다. 만약 데이터베이스와 애플리케이션 서버가 멀리 떨어져 있다면 그만큼 애플리케이션과 DB 서버의 통신 시간이 늘어니므로 늦게 응답을 받게 된다. 빠른 응답을 위해 애플리케이션 서버에 가깝게 서버를 구성하는 것이 좋다.
Replication의 원리
MySQL에서 Replication을 이해하려먼 바이너리 로그에 대해 알아야 한다.
바이너리 로그
MySQL 서버에서 발생하는 모든 변경사항을 별도의 로그 파일에 순서대로 저장한다. 여기서 변경사항은 다음과 같다.
- 데이터의 변경 내역
- 데이터베이스나 테이블의 구조 변경
- 계정이나 권한의 변경 정보
→ MySQL의 복제는 이 바이너리 로그를 기반으로 구현되었다.
MySQL에서 바이너리 로그 파일 확인하기
show binary logs;
바이너리 로그 파일 위치 기반으로 바이너리 로그를 식별할 때 사용하는 파일명과 위치 정보
show master status
소스 서버에서 생성된 바이너리 로그가 레플리카 서버로 전송되고, 레플리카 서버에서는 해당 내용을 로컬 디스크에 저장한 뒤 자신이 가진 데이터에 반영함으로써 소스 서버와 레플리카 서버 간에 데이터 동기화가 이루어진다.
이러한 과정의 복제는 MySQL의 세 개의 스레드에 의해 동작한다.
Binary Log Dump Thread
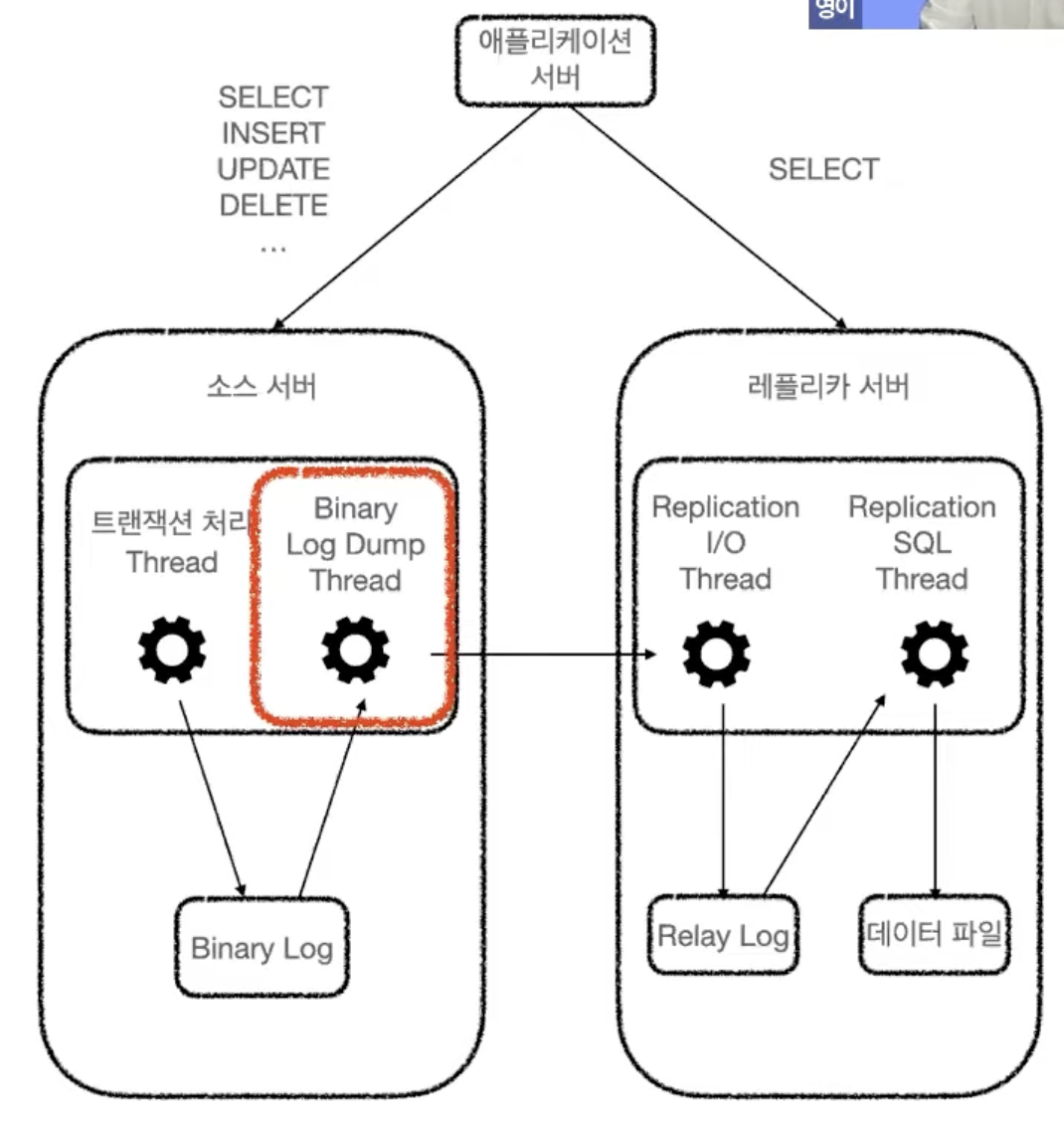
- 소스 서버에 존재한다.
- Binary Log를 레플리카 서버로 전송하는 역할을 수행한다.
- 레플리카 서버가 소스 서버에 연결되면 소스 서버에서 내부적으로 Binary Log Dump Thread를 생성한다.
Replication I/O Thread

- 레플리카 서버에 존재한다.
- Binary Log Event를 가져와 로컬 서버의 파일(Relay Log)로 저장한다.
- 복제가 시작되면 스레드가 생성되고, 복제가 멈추면 스레드는 종료된다.
- Connection Metadata: 소스 서버를 연결할 때 사용하는 정보를 가지고 있다. mysql.slave_master_info 테이블에 저장된다.
- Relay Log: 가져온 바이너리 로그 이벤트를 레플리카 서버에 파일로 저장한 것이다.
Replication SQL Thread

- 레플리카 서버에 존재한다.
- Replication I/O Thread에 의해 생성된 Relay Log 파일의 이벤트들을 읽고 실행한다.
- Applier: Relay Log에 저장된 소스 서버의 이벤트들을 서버에 적용하는 컴포넌트이다. 이벤트가 저장된 Relay Log 파일명과 파일 내 위치 정보를 담고 있으며, 이 정보를 바탕으로 레플리카 서버에 이벤트들을 적용한다.
- Applier Metadata: 소스 서버에 연결할 때 사용하는 정보를 가지고 있다. mysql.slave_relay_log_info 테이블에 저장된다.
어떻게 변경 내용을 식별하는가?
MySQL 복제를 사용하려면 소스 서버에서 반드시 Binary Log가 활성화돼 있어야 한다.
show master status를 통해 바이너리 로그 기록 여부를 확인할 수 있다.
바이너리 로그 변경 내역을 찾는 두 가지 방식
1. 바이너리 로그 파일 위치 기반 식별
레프리카 서버에서 소스 서버의 바이너리 로그 파일명과 파일 내에서의 위치로 바이너리 로그 이벤트를 식별해서 복제한다. 이벤트 하나를 소스 서버의 바이너리 로그 파일명과 위치 값의 조합으로 식별한다는 뜻이다.

이벤트가 최초로 발생한 MySQL 서버를 식별하기 위해 server_id를 사용한다.
기본값은 1인데 Replication을 하게 된다면 레플리카 서버에 반드시 server_id를 각각 다르게 지정해주어야 한다.
2. 글로벌 트랜잭션 ID 기반(GTID) 식별
복제에 참여한 서버들이 고유하도록 각 이벤트에 부여된 식별 값을 의미한다. 소스 서버에서 발생한 각 이벤트들이 복제에 참여한 모든 서버들에서 동일한 고유 식별 값을 가지도록 한다.
MySQL 5.5 버전까지는 바이너리 로그 파일 위치 기반 복제만 가능했다.
하지만 이 방식은 식별 과정이 소스 서버에서만 유효하다는 단점이 있다. 즉, 동일한 이벤트가 레플리카 서버에 동일한 위치와 동일한 파일명으로 저장된다는 보장이 없다. 어떠한 경우에는 동일한 이벤트임에도 서로 다른 식별 값을 가질 수도 있다.
이를 해결하기 위해 각 이벤트들이 복제에 참여한 모든 MySQL 서버들에서 동일한 고유 식별 값을 가지게 한다.
- 장점
- 장애가 발생해도 손쉽게 복제 토폴로지를 변경할 수 있다.
- 장애 복구에 소요되는 시간이 줄어든다.
바이너리 로그는 어떻게 생겼을까?
바이너리 로그는 3가지 형태가 존재한다.
1. Statement 방식
SQL문을 바이너리 로그에 그대로 기록하는 방식이다.
트랜잭션 격리 수준이 반드시 Repeatable-read 이상이어야 한다.
그 이하 방식에서는 하나의 트랜잭션 내에서도 각 쿼리가 실행되는 시점마다 스냅샷이 달라질 수 있는데, 이로 인해 복제 시 소스 서버와 레플리카 서버의 데이터의 불일치가 발생할 수 있다.
- 장점
- 손쉽게 SQL문들을 확인할 수 있다. - 단점
- 비확정적(delete/update에 order by 없이 limit 사용 등)으로 처리될 수 있는 쿼리가 실행된 경우, Statement 포맷에서는 복제 시 소스 서버와 레플리카 서버간 데이터가 달라질 수 있다.
2. Row 방식
데이터 변경이 발생했을 때 변경된 데이터 자체를 기록하는 방식이다.
MySQL 5.7.7 버전 이후부터 바이너리 로그의 기본 포맷이다.
- 장점
- 어떤 형태의 쿼리든지 복제 시 소스 서버와 레플리카 서버의 데이터를 일관되게 한다. - 단점
- 어떤 쿼리가 넘어왔고, 현재 실행중인 쿼리가 무엇인지는 확인하기 어렵다.
- 많은 데이터를 변경하면 모든 데이터가 전부 기록되어 바이너리 로그 파일이 단시간에 매우 커진다.
3. Mixed 방식
Statement 방식과 Row 방식을 혼합한 Mixed 방식이다.
쿼리의 대부분은 Statement 방식으로 기록될 확률이 높은데, 실행된 쿼리가 Statement 포맷으로 기록되어 복제됐을 때 문제가 될 가능성 있는 안전하지 못한 쿼리라면 Row 방식으로 기록한다.
복제 동기화 방식
소스 서버가 레플리카 서버에 이벤트들이 잘 보내졌는지 안보내졌는지 확인하냐 안하냐에 따라 복제 동기화 방식을 설정할 수 있다.
1. 비동기 복제

소스 서버가 레플리카 서버에서 변경 이벤트가 정상적으로 전달됐는지 확인하지 않는다.
소스 서버에 장애가 발생하면 소스 서버에서 최근까지 적용된 트랜잭션이 레플리카 서버로 전송되지 않을 수 있다.
2. 반동기 복제

소스 서버는 레플리카 서버가 소스 서버로부터 전달받은 변경 이벤트를 릴레이 로그에 기록 후 보낸 응답을 확인하면 그때 트랜잭션을 완전히 커밋한다.
하지만 전송이 보장된 것이지 적용이 보장된 것은 아니다.
또한 서버의 응답을 기다리기 때문에 비동기 방식보다 트랜잭션 처리가 길어질 수 있다. 응답이 오지 않으면 무기한적으로 기다릴 수 있기 때문에 소스 서버는 지정된 타임아웃 시간동안 응답이 없으면 비동기 복제 방식으로 전환된다.
소스 서버와 레플리카 서버를 어떻게 구성할까?
1. 싱글 레플리카 복제

하나의 레플리카 서버만 연결되어 있다.
소스 서버에 문제가 생겼을 때 예비 서버 및 데이터 백업 수행을 위한 용도로 사용한다.
2. 멀티 레플리카 복제

하나의 소스 서버에 2개 이상의 레플리카 서버가 구성되어 있다.
하나의 서버는 예비용으로 구성하고, 다른 서버는 읽기 요청 처리를 분산하는 용도로 사용한다.
3. 체인 복제

하나의 소스 서버에 연결된 레플리카 서버 수가 많을 경우 바이너리 로그를 읽고 전달하는 작업 자체가 부하가 될 수 있을 때 사용한다.
소스 서버가 해야 할 바이너리 로그 배포 역할을 새로운 서버로 넘긴다.
4. 듀얼 소스 복제
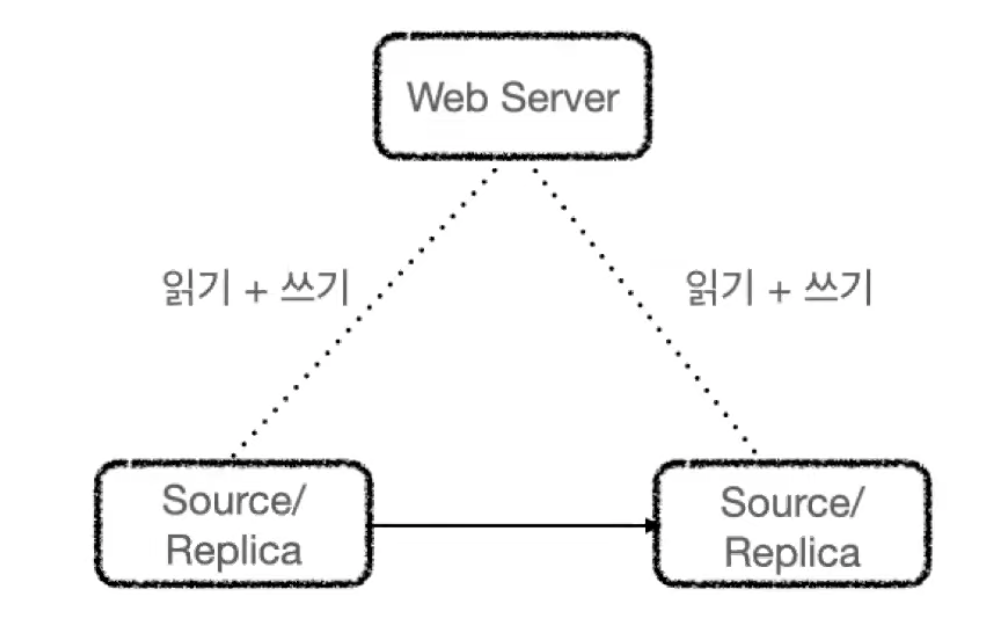
두개의 서버가 서로 소스 서버이자 레플리카 서버로 구성되어 있다.
두 서버 모두 쓰기가 가능하며, 각 서버에서 변경한 데이터는 복제를 통해 다시 각 서버에 적용되므로 양쪽에서 쓰기가 발생하지만 두 서버는 서로 동일한 데이터를 갖게 된다.
목적에 따라 ACTIVE-PASSIVE 형태, ACTIVE-ACTIVE 형태로 사용할 수 있다.
싱글 레플리카와 비슷해 보이지만 한 서버에 장애가 일어날 경우 전환을 바로 가져갈 수 있다.
5. 멀티 소스 복제

하나의 레플리카 서버가 둘 이상의 소스 서버를 갖도록 구성되어 있다.
여러 서버에 존재하는 다른 데이터를 하나의 서버로 통합하거나, 샤딩되어 있는 테이블 데이터를 하나의 테이블로 통합할 때 사용할 수 있다.
샤딩이란?
같은 테이블 스키마를 가진 데이터를 다수의 데이터베이스에 분산하여 저장하는 방법을 의미한다.

'CS' 카테고리의 다른 글
| [OS] Blocking vs Non-Blocking, Sync vs Async (0) | 2025.02.18 |
|---|---|
| [DB] NoSQL (1) | 2024.04.06 |
| [Network] 프록시(Proxy) (0) | 2024.04.06 |
| [자료구조] 힙(Heap) (0) | 2024.03.07 |
| [SE] OOP란? (1) | 2024.03.04 |